Knowledge Doping Process
Generative AI outputs from foundation models are general or make up details. To combat this, we inject relevant context that includes, for example, up-to-date product information, current user details, or search results from a public or private index. Thus, the model doesn’t need to get creative with facts because it can draw on relevant context provided in the prompt.
There are limits to how much context we can provide, and also, more context equates to higher token counts and therefore costs. To get the best value, we need to be concise and precise with the context provided.
A Semantic Search Index is used to find the most relevant context. The semantic part of the search index uses embeddings (model encodings of the text) to find content close in meaning instead of relying on keyword matches. As knowledge becomes more specific, the semantic capabilities become more important.
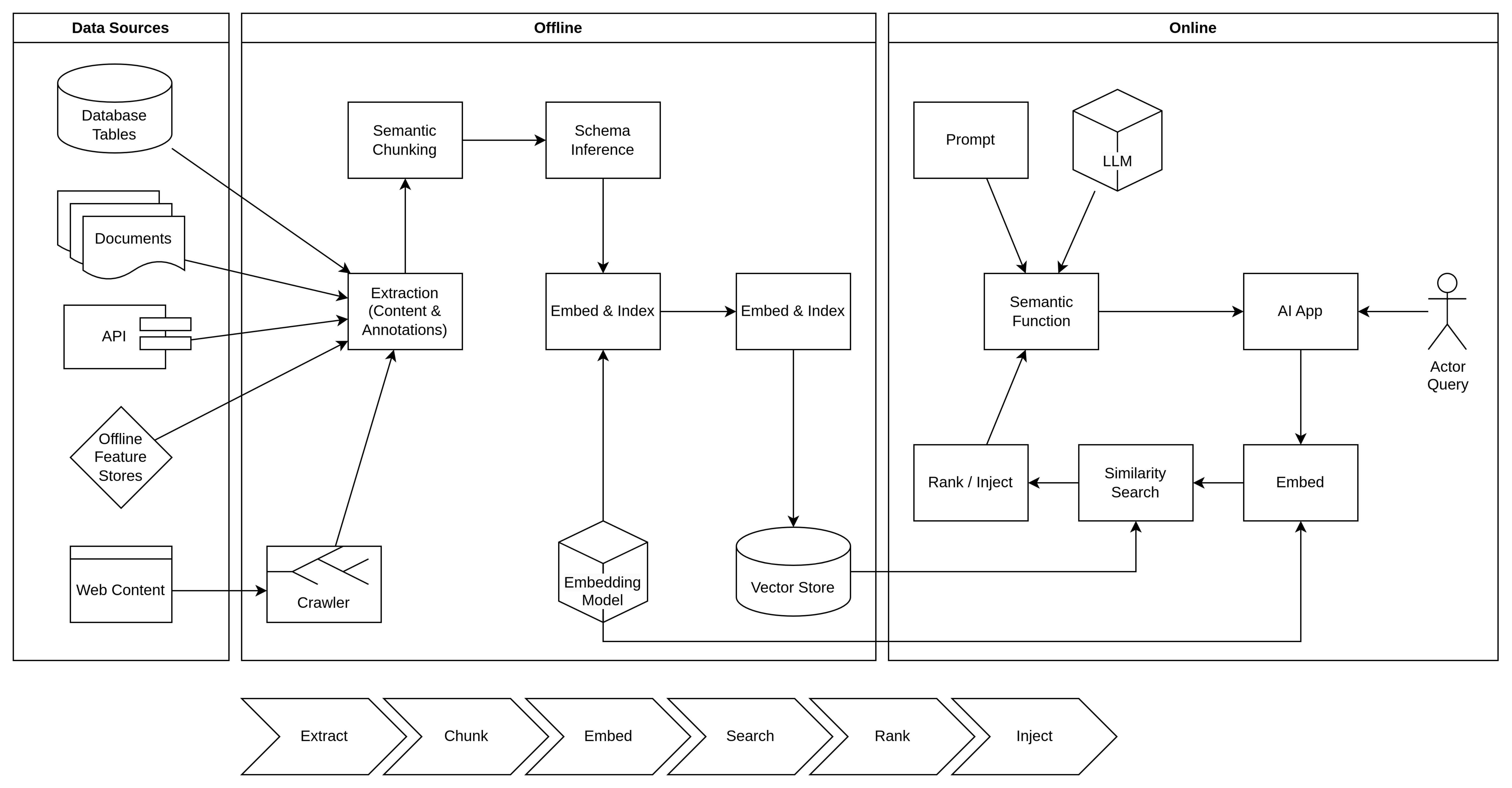
Data sources include:

As a scheduled or triggered process, fresh content is crawled, extracted, chunked, and is processed to create embeddings stored in a vector database.

At runtime, a user query is converted into an embedding vector that is used to perform a similarity search across the vectors stored in the vector database. (For scalability, the vector database should support push-down search. That is, the similarity search algorithm, such as HNSW should be implemented within the database to avoid pulling all embeddings out of the database to perform the search.)

The top ranked search results are injected into the prompt to enable the semantic function to return a relevant and “non-hallucinated” response.