Semantic Indexes
A Semantic Index is a type of Search Index. The process of creating an index is as follows.

- Extract. Extract text from one or more data sources. A data source could be a document, a folder of documents, an API, or a database table. Document formats could include PDF, Word, CSV, etc. The extraction process might involve OCR (optical character recognition) processing of image based forms and articles, extracting text from a proprietary format such as PDF, transcribing audio or video, and even generating textual descriptions from a collection of images.
- Chunk. Break the text into “chunks”. A naive approach to chunking is to split the text by sentence or paragraph, or by fixed token lengths. A better approach is to use a chunking model that divides the text into semantically coherent sub-segments (topically similar units). The intuition here is that long pieces of text usually consist of multiple themes, topic, problems, solutions, sentiments, etc. Chunking text according to topic or sentiment breaks will be a better fit for purpose to serve knowledge doping applications.
- Embed. Calculate an embeddings vector for each chunk of text and store in a database. Vector databases such as Milvus, Redisearch, Chroma, Weaviate, and Pinecone are custom built for this purpose. Sometimes the database provides the embedding function, or we use a language model such as Universal Sentence Encoder or the OpenAI Embeddings API.
- Search. Convert the user query into an embeddings vector and perform a similarity search across the stored vectors for all other chunks in the index. Similarity search implementations include the Facebook AI Similarity Search (FAISS) library, and implementations built into a number of vector databases. Hierarchical Navigable Small Worlds (HNSW) graphs are among the top-performing indexes for vector similarity search. HNSW is a hugely popular technology that produces state-of-the-art performance with super-fast speeds and near flawless recall.
- Rank. Rank search results using the similarity distance score.
- Inject. Populate top hits into the prompt for the LLM to use as just-in-time knowledge.
A Semantic Index manages steps 1 through 5, and provides a service to accomplish step 6.
Hybrid Search
Searching across vectors is useful for finding relevant text. However, the more capable solutions support Hybrid Search that allows searching across both the embedding space and categorical data include time. Time travel in particular is a key capability not supported by all vector database solutions.
Historically, a weakness of both knowledge graphs and vector databases is the inability to search within slices of time that would give us insight into changing metrics and patterns over time. In traditional data warehousing we maintain slowly changing dimensions (SCD Type 2) to track changes and give us the ability to look at information at a point in time. Modelling time in graph and vector databases has been a greater challenge although there are database options in each category to support this. Terminus DB for graph and Milvus for Vector are two options that come to mind.
Hybrid Search accepts a query consisting of a text field and one or more facets, which enables faceted search - the ability to restrict search results by, say, time range, product category, location, etc.
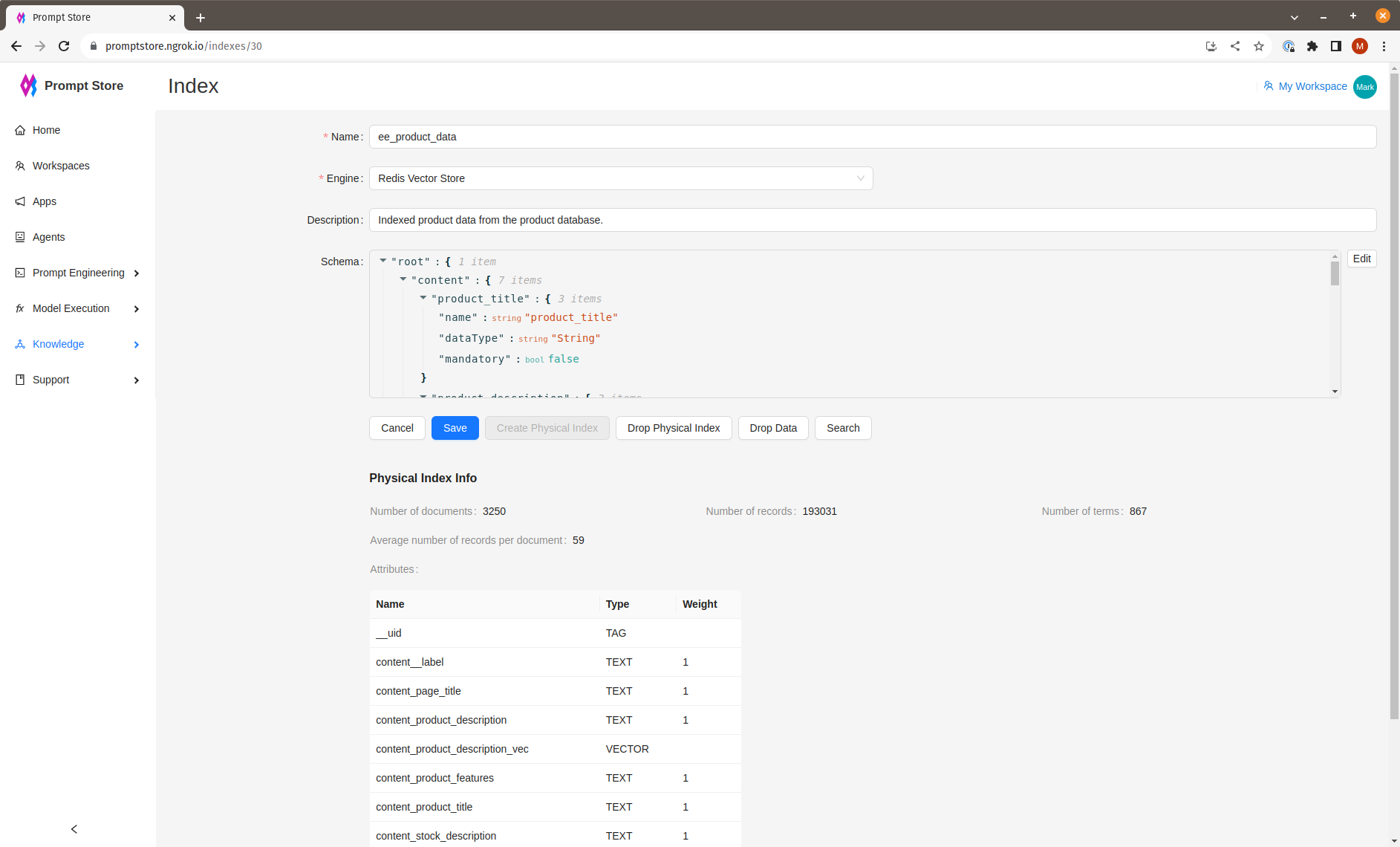
Schema Definition
A Semantic Index has a logical schema that is translated into a physical schema appropriate to the underlying data store. An example of the logical schema is
{
"content": {
"type": {
"name": "type",
"dataType": "String",
"mandatory": false
},
"text": {
"name": "text",
"dataType": "Vector",
"mandatory": false
}
}
}Fields with a Vector data type will generate an additional column for the embeddings.
The logical schema is converted into a physical schema for the store.

Schema Inference
For some sources, the schema can be inferred, and the process of generating both logical and physical schemas completely automated.
For other sources, the logical schema can be customised.
What is an Embedding?
An embedding is a string of numbers that uniqely identifies a chunk of text. The numbers plot the chunk of text in a space. Instead of two dimensions like on a sheet of paper, or three dimensions as in a physical space such as a room, embeddings map chunks of text in a space defined by hundreds of dimensions. But just like a physical space, chunks of text related in meaning are close to each other in this multidimensional space. Semantic Search first converts the user’s query into an embedding, and then finds chunks of text near by in the multidimensional space. The relative Euclidean distance determines the ranking of search results. How the embeddings are calculated is a more in depth explanation, but you can find more details here.
Create New Indexes
Although indexes can be manually created, the recommended approach is to index a Data Source, which will infer all of the index settings and create the index automatically.
To view the list of indexes or create a new index, click on “Indexes” under “Knowledge” in the left side menu.
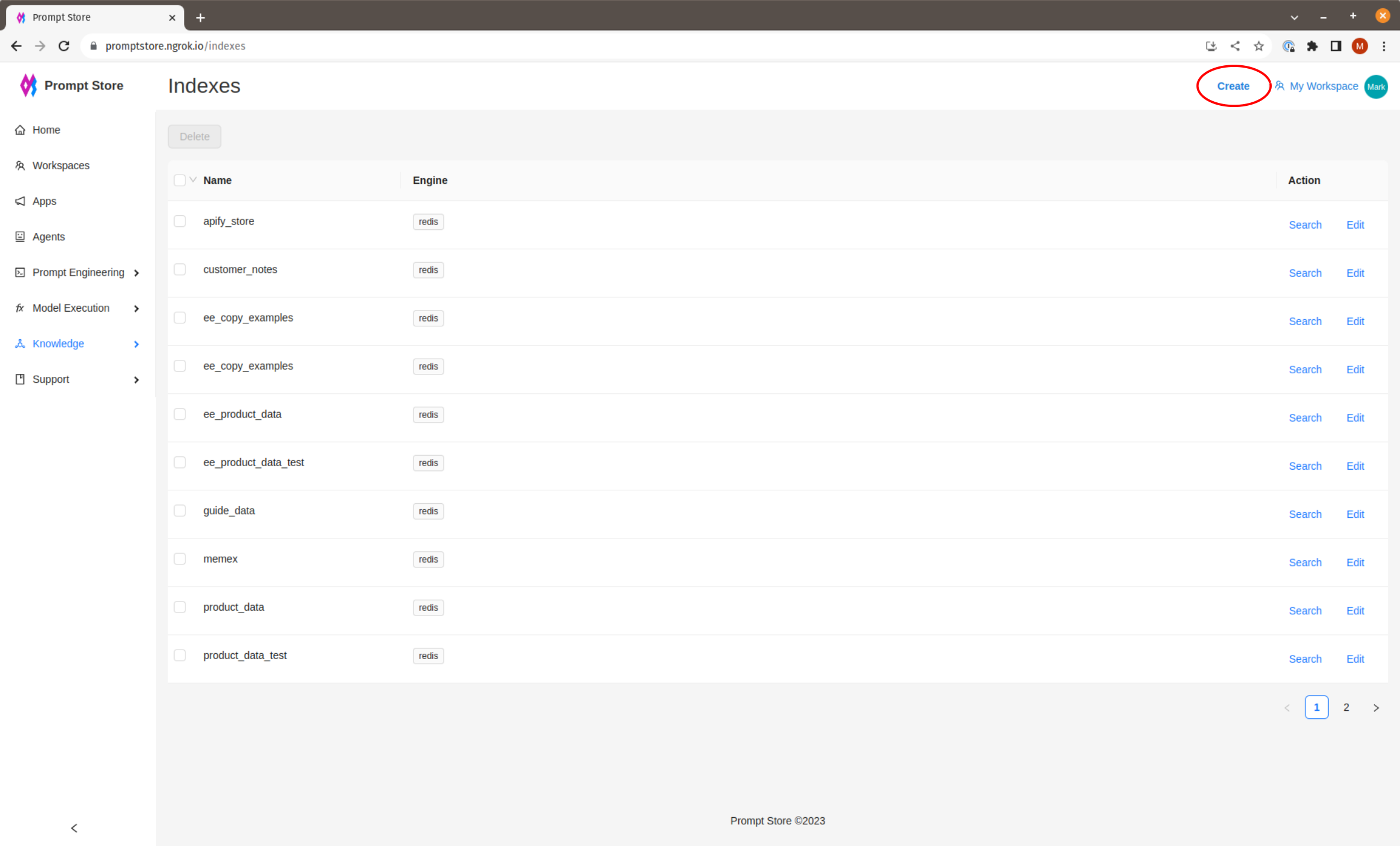
Click “Create” in the top Nav bar to create a new index.