Semantic Functions
Think of a Semantic Function as like a regular code function. Name it as you would functions in your code. (The Client SDK makes it easy to use semantic functions in your code, so using the same naming convention will support existing linters and keep your code style consistent.)
A Semantic Function can be tagged to find related functions - for example, all functions used in copy generation.
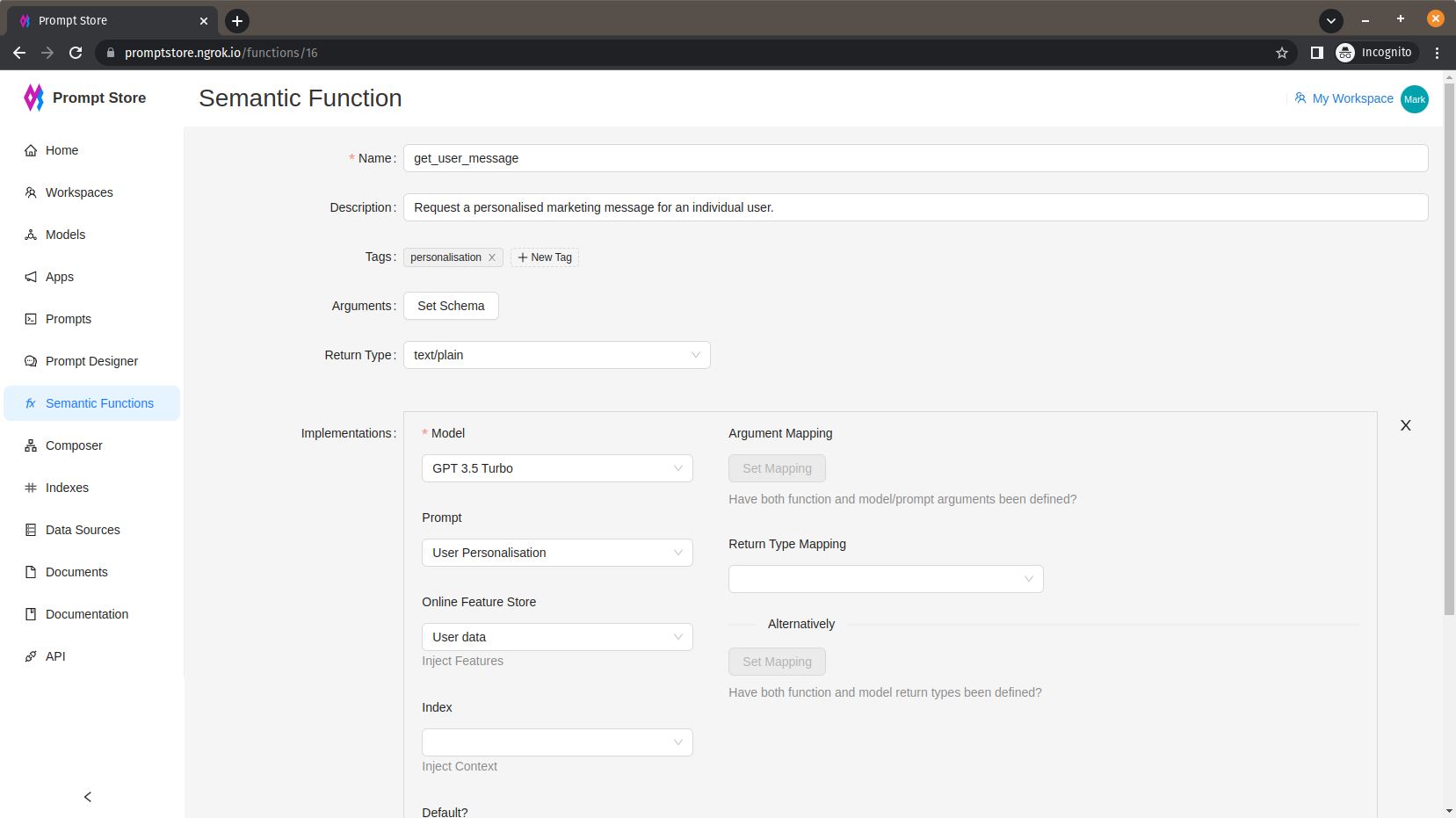
Function arguments and outputs can be defined using JSON Schema as for Prompt arguments.
Create New Functions
To view the list of functions or create a new function, click on “Semantic Functions” under “Model Execution” in the left side menu.
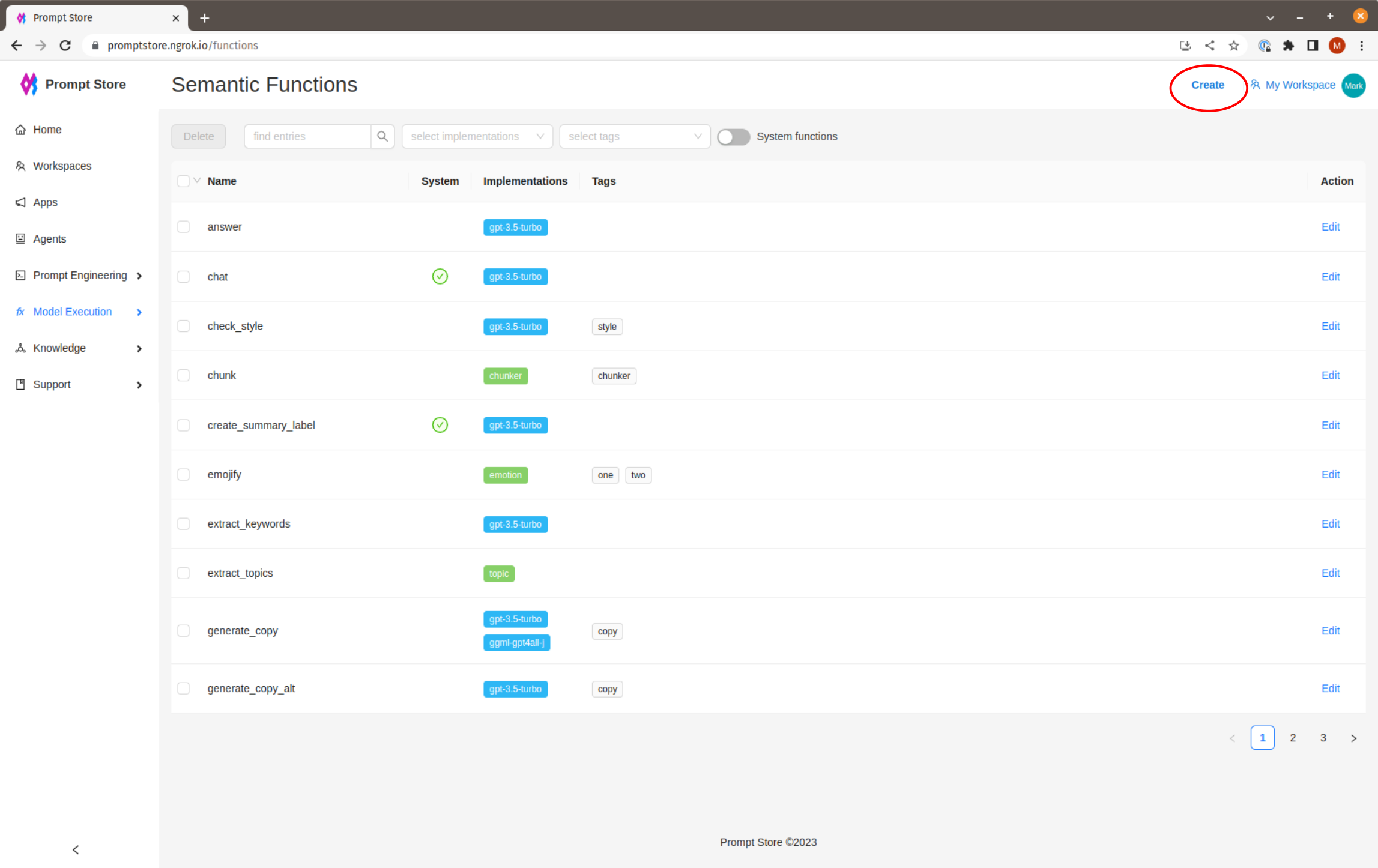
Click “Create” in the top Nav bar to create a new function.
To find a function, other than by ID, we can attach a skill and one or more tags, then search by skill or tag.
Input Validation
Any function is at risk of “garbage in - garbage out”. To ensure that the function receives all the expected input arguments, we can define a schema. In a programming language, this would be the equivalent of using a type-safe language or typing hints to ensure that a) the right parameters are received, and b) each parameter has the expected data type such as “String”, “Number”, or “List of Numbers”.
While specifying a schema is optional, it is recommended. An LLM will work with whatever you give it, so it isn’t easy to see why the model is returning subpar results. It may be that the application is not providing all the required inputs, and this bug is going undetected. Argument checking catches these issues during development and testing prior to launching with real users.
Output Formatting
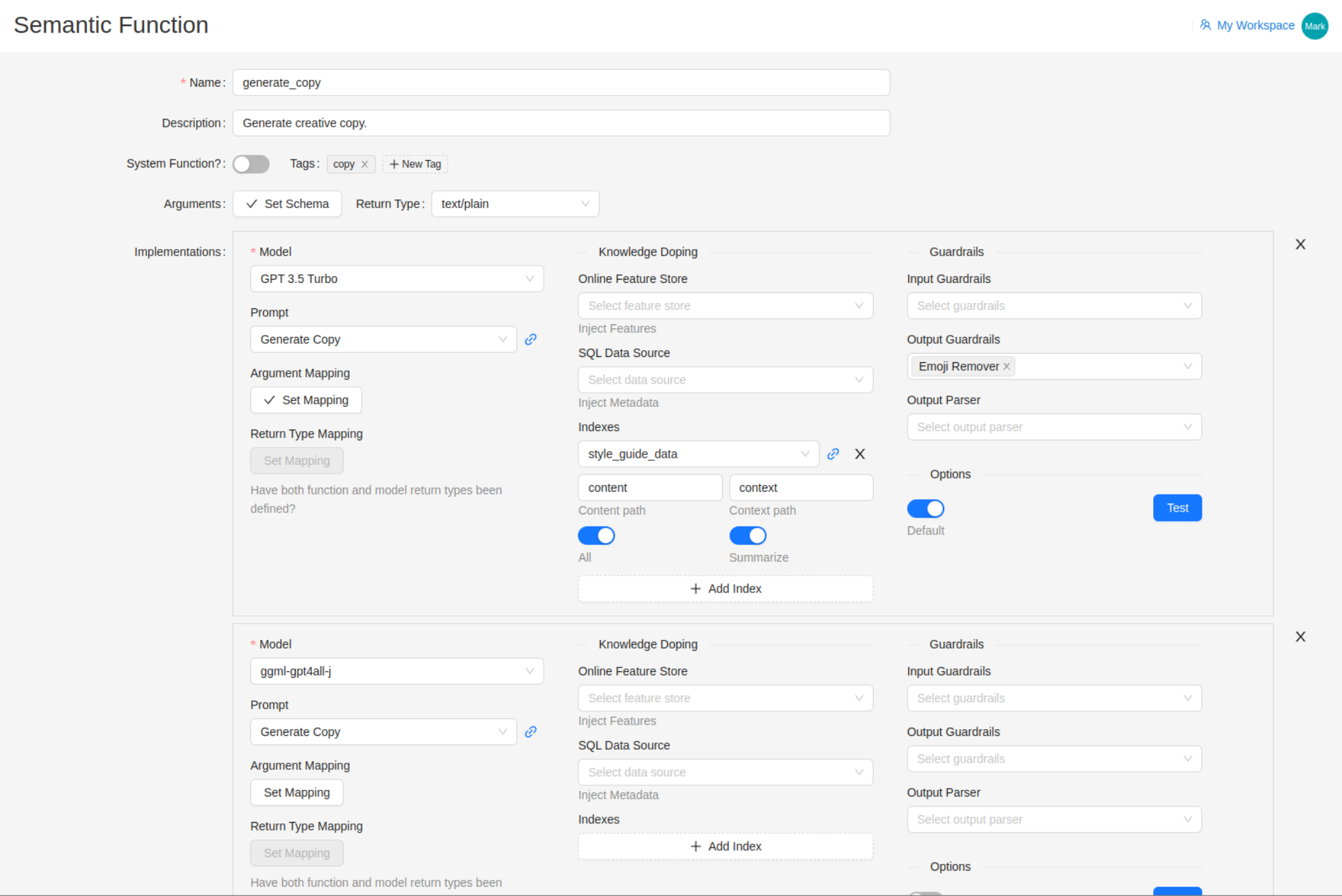
For when we want structured output from the model such as JSON, we can use an Output Parser to validate, and if possible, fix the output. Other options include removing quotes or emojis, and extracting a true/false response including all the ways to express a boolean result - “yes”, “True”, etc.

Knowledge Doping
A standard pattern for Generative AI applications involving enterprise or specialised data is to index documents using embeddings, store the embeddings in a vector database, find relevant “chunks” of text using similarity distance across the embeddings against the user query, and populate the prompt with the highest ranking results to answer the query.
Prompt Store provides tools to perform this indexing. One or more indexes can be attached to semantic function to automatically inject knowledge into the prompt.
This is a key technique to mitigate the risk of “hallucinating” information in LLM responses.

Guardrails
Guardrails are applied before and after a model is called. An example of an input guardrail is to detect any personally identifiable information (PII) such as name or address before information is sent to an external model. Even if the model is secure, data can be at risk of “man in the middle” attacks in transit. The PII Detector can be configured to stop the request and raise and alert. Alternatively, it could route the request to an internally hosted private model instance.

Support Multiple Implementations
A Semantic Function can have more than one implementation. An implementation is defined as linking to a particular model.
We support multiple implementations for the following reasons:
- So we can switch the model to a private instance for a particular use case without having to change the code
- To enable A/B testing across multiple model instances
- To support different service levels
For example, GPT-4 may perform better than GPT-3.5 for a particular task. However, GPT-4 is more expensive and can be slower. Having more than one implementation allows us to support different operational requirements:
- Use Case 1. Model reasoning is more important than application performance because the application is supporting a small number of users undertaking a task where accuracy is a priority. Use a model that prioritizes reasoning capability over speed.
- Use Case 2. Application performance and cost is more important than model capability because the application must support a large number of users, and the application is more tolerant of errors. Use a cheaper, faster model.
Model Types
Models that can be used with semantic functions include GPT models such as OpenAI GPT-4 and GPT-3.5, Google PaLM 2, Anthropic Claude, and other models such as from Hugging Face or custom in-house language models.
Implementation Options
For GPT-style models, we specify the prompt and one or more data sources.
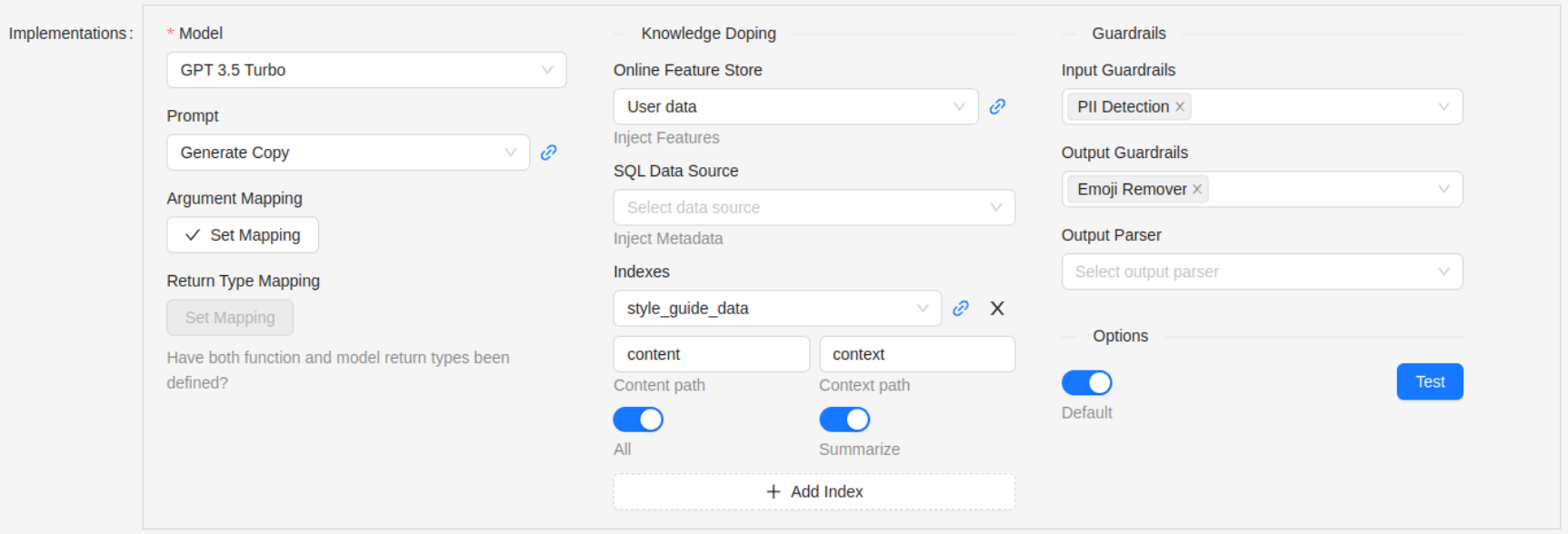
The Online Feature Store option is used to lookup data for an entity, such as a customer, driver, etc., and populate dynamic variables within the prompt prior to model execution.
An Index is a knowledge store such as a Vector Database. The prompt is sent as a query to the vector database to perform a search for relevant content. Alternatively, all entries from a given index can be returned. This content is then inserted into the prompt, usually just before the user input, to augment the model with additional information from which to draw the response.
This technique has been colloquially called “knowledge doping” because we are feeding the model with additional relevant knowledge that only exists in a private source.